
Peking, sechs Gigawatt: Wie Chinas KI den Chip-Mangel in einen Preisvorteil verwandelt
Während die USA ihre Chip-Exportbeschränkungen verschärfen, baut China eine KI-Infrastruktur auf, die nicht auf bessere Chips setzt, sondern auf billigere Token – und damit das Rennen von einer anderen Seite aufrollt.
Die Rechnung ist einfach, aber ihre Folgen sind es nicht. Ein Ingenieur in Peking lässt ein KI-Modell eine Code-Bibliothek durchforsten. Die Antwort kommt in Sekunden – und kostet weniger als ein Cent. Sein Kollege in San Francisco stellt dieselbe Frage an ein US-Modell. Die Antwort ist marginal besser, aber fünfzehnmal teurer. Was wie eine Anekdote aus dem globalen KI-Alltag klingt, ist das zentrale Manöver in einem Strategiewechsel, der die Machtverhältnisse der Branche neu justieren könnte.
Kernzahlen:
- DeepSeek V3 wurde für 6 Mio. USD trainiert, GPT-4 kostete schätzungsweise 100 Mio. USD – ein Faktor 16.
- MiniMax M2.5 kostet auf OpenRouter 0,30 USD pro Mio. Input-Tokens, Claude Opus 4.6 dagegen 5 USD – ein Sechzehntel.
- Chinas Wind- und Solarkapazität erreichte Ende 2025 1,84 Mrd. kW – 47,3 % der Gesamtleistung.
- Baidus ERNIE X1 bietet laut Eigenangaben DeepSeek-R1-Leistung zum halben Preis.
Die Chip-Falle, die keine ist
Auf den ersten Blick haben die US-Sanktionen ihr Ziel erreicht. Seit Oktober 2023 sind selbst die abgespeckten Nvidia-Chips A800 und H800 für China tabu. Die Lücke zu den besten US-Beschleunigern beträgt laut einer Analyse vom Herbst 2025 etwa das Fünffache – und soll bis 2027 auf das Siebzehnfache anwachsen. Wer nur auf die Rechenleistung pro Chip schaut, sieht einen Vorsprung, der uneinholbar scheint.
Doch AMD-CEO Lisa Su zeichnete im Mai 2025 vor dem US-Senat ein anderes Bild. KI-Wettbewerbsfähigkeit erfordere „actually excellence at every layer of the stack“ – also Exzellenz auf jeder Ebene des Systems, vom Silizium über die Software bis zur Energieversorgung. Ein Engpass auf einer Ebene reicht nicht, um das Ganze zu sichern. China hat diese Botschaft offenbar verinnerlicht und setzt nicht auf die eine Wunderwaffe, sondern auf ein ganzes Arsenal.
Die drei Hebel der chinesischen Token-Ökonomie
Der erste Hebel ist algorithmische Effizienz. DeepSeek trainierte sein V3-Modell für 6 Millionen Dollar – ein Bruchteil der geschätzten 100 Millionen, die OpenAI für GPT-4 ausgab. Möglich macht das die Mixture-of-Experts-Architektur (MoE), bei der nicht alle Parameter eines Modells bei jeder Anfrage aktiviert werden. Chinesische Entwickler kompensieren mit dieser strukturellen Effizienz, was ihnen an roher Silizium-Power fehlt.
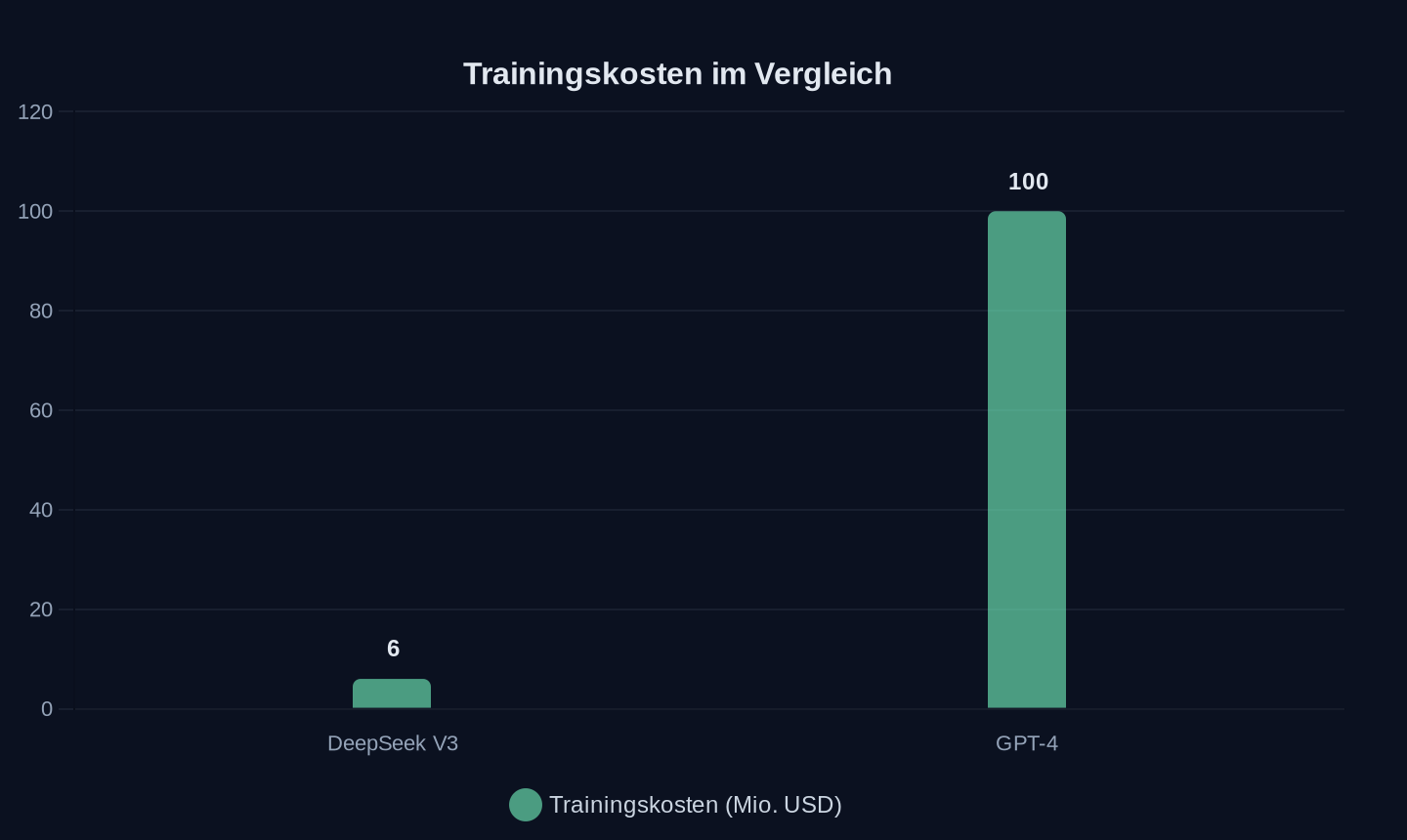 Trainingskosten in Millionen USD
Trainingskosten in Millionen USD
Der zweite Hebel sind die Energiekosten. Ende 2025 speisten Chinas Wind- und Solarkraftwerke 1,84 Milliarden Kilowatt ins Netz – 47,3 Prozent der gesamten installierten Leistung. Chinesische Stromkosten liegen 30 bis 50 Prozent unter denen der USA. Das Changjiang Securities Research Institute bezeichnet Tokens deshalb als „Stromderivat“ – denn Strom macht 60 bis 70 Prozent der Betriebskosten großer Modelle aus. China exportiert also nicht nur KI-Dienstleistungen, sondern indirekt auch seinen günstigen Strom, ohne eine einzige Kilowattstunde über die Grenze zu schicken.
Der dritte Hebel ist die aggressive Preisgestaltung. MiniMax M2.5 verlangt auf OpenRouter 0,30 Dollar pro Million Input-Tokens, Anthropics Claude Opus 4.6 dagegen 5 Dollar – ein Sechzehntel. Und dieser Preisunterschied geht nicht zulasten der Qualität. Auf SWE-Bench Verified, dem Goldstandard für Code-Benchmarks, erreicht M2.5 80,2 Prozent – Claude Opus 4.6 liegt bei 80,8 Prozent. Die Differenz: 0,6 Prozentpunkte. Der Kostenunterschied pro Aufgabe: ein Faktor 20.
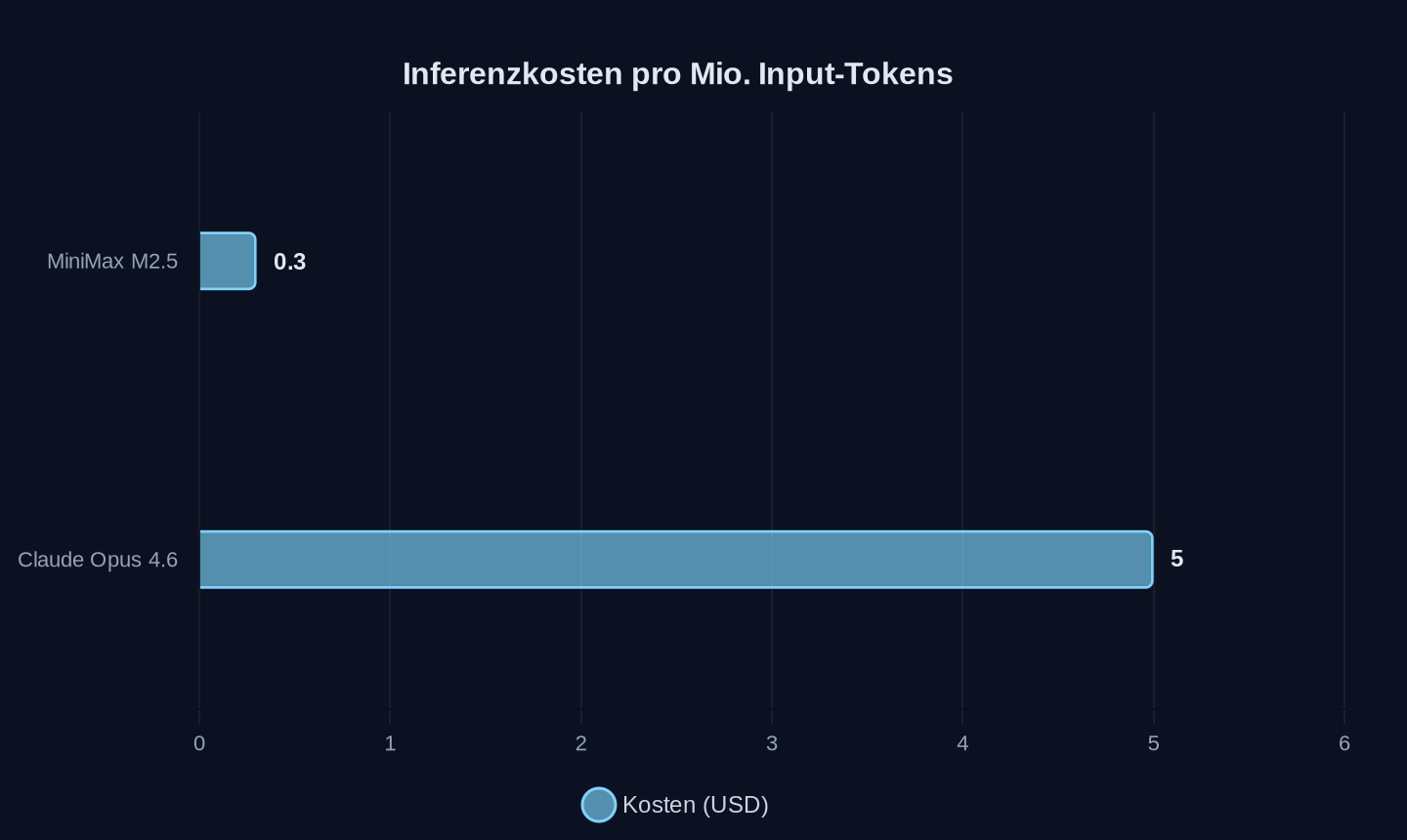 Kosten pro Million Input-Tokens in USD
Kosten pro Million Input-Tokens in USD
Die unbequeme Wahrheit hinter den Benchmarks
Doch so beeindruckend diese Zahlen sind – sie erzählen nicht die ganze Geschichte. Ein genauerer Blick auf die veröffentlichten Benchmarks offenbart ein Muster: Die chinesischen Modelle glänzen vor allem dort, wo sie trainiert wurden. Auf SWE-Bench, einem Coding-Benchmark, liegen sie etwa gleichauf. Bei abstrakter Logik (ARC-AGI) oder mathematischem Denken (AIME) klafft die Lücke zu den US-Spitzenmodellen wieder auf.
Hinzu kommt ein strukturelles Problem: Die Inferenzgeschwindigkeit. Chinesische Modelle laufen auf heimischen Chips wie Huaweis Ascend 950 oder Alibabas PPU. Diese sind zwar günstiger und werden zunehmend konkurrenzfähig – aber sie erreichen nicht die rohe Durchsatzleistung von Nvidias Blackwell-Systemen. Für latenzkritische Anwendungen wie Echtzeit-Sprachassistenten oder interaktive Code-Editoren kann das ein entscheidender Nachteil sein.
Das Spiel mit dem Feuer: Chinas regulatorisches Paradox
Chinas Premierminister Li Qiang forderte auf der Weltkonferenz für Künstliche Intelligenz (WAIC) 2025: „Only by adhering to openness, sharing and fairness in access to intelligence can more countries and groups benefit from (AI)“. Das klingt nach globaler Zusammenarbeit. Doch die Realität ist komplexer.
Seit 2023 betreiben die chinesischen Behörden ein strenges Registrierungssystem für KI-Modelle. Bis April 2025 waren 868 Dienste gemeldet. Jedes Modell muss vor der Veröffentlichung eine Sicherheitsprüfung durchlaufen, einen Keyword-Intercept-Liste vorlegen und nachweisen, dass es die sozialistischen Kernwerte widerspiegelt. Der Vorgang dauert drei bis sechs Monate. Das ist kein Widerspruch zur Forderung nach Offenheit – es ist ihre chinesische Interpretation: Offenheit nach innen, Kontrolle nach außen.
Was das für Europa bedeutet
Für deutsche Unternehmen und Zulieferer wie Bosch, ZF oder Continental eröffnet diese Entwicklung ein Dilemma. Die chinesischen Modelle sind günstig, leistungsfähig und zunehmend in europäischen Cloud-Plattformen verfügbar. Ein mittelständisches Ingenieurbüro könnte seine Code-Generierung für einen Bruchteil der bisherigen Kosten auf chinesische Modelle verlagern – und würde damit in ein regulatorisches Minenfeld treten.
Denn ein deutsches Gericht hat jüngst entschieden, dass Google für KI-Halluzinationen haftbar ist. Der Präzedenzfall könnte die gesamte Branche erfassen. Wer ein chinesisches Modell in seine Produktionskette integriert, übernimmt nicht nur die Kosten, sondern auch das Risiko – und das ist mit keinem Preisnachlass zu bezahlen.
Drei Szenarien für die nächsten Jahre
Szenario 1: Die Token-Ökonomie siegt. Die chinesischen Modelle halten ihr Leistungsversprechen, die Preise fallen weiter, und die Weltmarktanteile verschieben sich. Westliche Anbieter müssen ihre Preise drastisch senken oder ihre Modelle für spezifische Nischen optimieren. Der Wettbewerb wird zum Preiskampf – und China hat die günstigere Energie.
Szenario 2: Die Chip-Lücke bleibt entscheidend. Die US-Sanktionen zeigen langfristig Wirkung. Chinesische Chips erreichen nicht die nötige Durchsatzleistung, die Inferenzgeschwindigkeit bleibt ein strukturelles Hindernis. Für latenzkritische Anwendungen setzen Unternehmen weiterhin auf US-Modelle – und zahlen den Premiumpreis.
Szenario 3: Die regulatorische Fragmentierung. Europa baut eigene KI-Standards auf, die sowohl US- als auch chinesische Modelle betreffen. Die Haftungsfrage wird zum zentralen Thema. Unternehmen müssen für jedes Modell nachweisen, dass es den europäischen Anforderungen genügt – ein teurer Prozess, der die Kostenvorteile chinesischer Modelle zunichtemacht.
Der Preis der Freiheit
Chinas KI-Strategie ist klug, aber nicht risikolos. Sie setzt auf Effizienz statt auf rohe Kraft, auf Preis statt auf Exklusivität. Doch sie übersieht, dass der Preis eines Tokens nicht nur in Dollar gemessen wird – sondern auch in Vertrauen, in Haftung, in Regulierung. Die Frage ist nicht, ob chinesische Modelle billiger sind. Sie sind es. Die Frage ist, ob billig genug ist, um die Risiken aufzuwiegen. Und das ist eine Frage, die nicht in Peking, sondern in Brüssel, Berlin und Stuttgart entschieden wird.
Quellen
- China’s Plan for Winning the AI Race Hinges on the Token Economy, Not Chips
- China calls for global 'consensus' on AI regulation
- China launches AI framework to improve ‘black box’ transparency and raise standards
- A Court Has Ruled That Google Is Liable for False Statements Generated by AI Overviews
- Learning to lead in a hybrid human-AI enterprise
- SpaceX is now a public company valued for its AI potential, so what comes next?
- Miss Hong Kong stirs Cantonese debate, China cuts degrees in AI push: 5 weekend reads you missed
- Baidu’s Apollo Go begins Swiss road tests With PostBus autonomous service
- 健康AI阿福测试“医生把关”新功能:打开“AI+医生”协作想象空间
- 2026北京智源大会开幕 | 从“悟道”到“悟界”,智源研究院推动人工智能、物理世界和生命科学“三体互动”
- Pakistani gig workers' exports to hit record high but AI threats loom
- Zhipu soars and Minimax stumbles as China's AI stocks diverge
- Is Richard Dawkins Right About Claude? No. But It’s Not Surprising AI Chatbots Feel Conscious to Us.
Weitere Artikel

Null Prozent, 41 Prozent, 295 Milliarden: Chinas Chip-Ersatzmarkt
15. Juni 2026

Lithium, Eisen, Natrium – und ein Technologiesprung, der Chinas Macht brechen könnte
14. Juni 2026

63 Prozent Marktanteil – Chinas EV-Hersteller opfern die Heimat für die Welt
14. Juni 2026

Zollschach: Wer wirklich die Rechnung zahlt
13. Juni 2026

Blitzladen, Puppenköpfe, Bürokratie – Chinas E-Auto-Offensive spaltet Europa
13. Juni 2026

Chinas Smart-City-Exporte blenden Bürgerrechte aus und riskieren Sicherheitslücken in Europa
12. Juni 2026

Chinas Roboautos fahren weiter – während der Westen noch zählt
12. Juni 2026

Chinas Batteriefabriken produzieren die Zukunft ohne Europa
12. Juni 2026

„Wer es als Erster schafft, gewinnt den Nobelpreis“ – Chinas Roboter-Revolution frisst ihre Kinder
11. Juni 2026

Chinas KI-Modelle erobern den Markt – nicht mit Chips, sondern mit Strom
11. Juni 2026

Chinas Smart Cities atmen CO₂ und Datenmüll
10. Juni 2026

Huawei und SMIC zwingen die USA zur nächsten Sanktionsrunde
10. Juni 2026