
DeepSeek, Tencent, Xiaomi — wie chinesische KI-Modelle die US-Dominanz auf OpenRouter brechen
Im Juni 2025 kontrollierten US-Modelle noch 70 Prozent des Token-Volumens auf OpenRouter, ein Jahr später nur noch 30 Prozent. Chinesische Anbieter wie DeepSeek, Tencent und Xiaomi haben die Mehrheit übernommen — nicht durch bessere Modelle, sondern durch radikale Inferenz-Effizienz und aggressive Preise. Der Artikel zeigt, wie DeepSeeks DSpark-Algorithmus die Generierung um bis zu 85 Prozent beschleunigt und die Kostenstruktur der KI-Industrie neu definiert.
Im Juni 2025 kontrollierten US-amerikanische KI-Modelle noch rund 70 Prozent des Token-Volumens auf OpenRouter, einem neutralen Marktplatz, auf dem Entwickler und Unternehmen ohne Vendor-Lock-in zwischen Dutzenden Modellen routen. Ein Jahr später ist dieser Anteil auf etwa 30 Prozent gefallen. Chinesische Modelle von DeepSeek, Tencent, Xiaomi und MiniMax verarbeiten inzwischen die Mehrheit der Token auf der Plattform. Das ist keine Momentaufnahme, kein kurzfristiger Hype. Es ist eine strukturelle Verschiebung, die sich in den vergangenen zwölf Monaten Zug um Zug vollzogen hat — und die im Westen weitgehend unbemerkt blieb.
Der entscheidende blinde Fleck im Westen ist nicht, ob China aufholt. Sondern dass chinesische KI-Unternehmen die Inferenz-Effizienz als strategische Waffe einsetzen — während US-Firmen in teuren Trainings-Wettrüsten stecken. DeepSeek hat die Generierungsgeschwindigkeit seines V4-Modells um 85 Prozent gesteigert, ohne neue Hardware, ohne größeres Modell, nur durch einen schlauen Algorithmus namens DSpark. Die eigentliche Disruption ist nicht das Modell. Es ist die Systemoptimierung.
Die wichtigsten Zahlen:
- US-Modelle auf OpenRouter: von 70% auf 30% Token-Anteil gefallen (Juni 2025 vs. Juni 2026)
- DeepSeek V4-Pro-DSpark: 60–85% schnellere Generierung pro Nutzer bei gleichem Durchsatz
- DeepSeek V4-Pro: $1.071 vs. $4.811 für Claude Opus 4.7 im AI-Index-Benchmark — mehr als 4x günstiger
- Anthropic: Run-Rate-Umsatz von 47 Mrd. Dollar im Mai 2026 — wie viel davon aus Asien?
- Chinesische KI-Startup-Finanzierung: 16,2 Mrd. Dollar im ersten Quartal 2026, ein Anstieg von 185% gegenüber dem Vorjahr
Die unsichtbare Waffe
Am 27. Juni 2026 veröffentlichte DeepSeek eine Reihe von Open-Source-Lösungen, die auf den ersten Blick unspektakulär wirkten. Kein neues Modell, kein bahnbrechender Durchbruch bei den Fähigkeiten. Stattdessen: ein Framework für spekulative Dekodierung namens DSpark, ein Trainingsframework namens DeepSpec, und zwei neue Checkpoints — DeepSeek-V4-Pro-DSpark und DeepSeek-V4-Flash-DSpark. Die Modelle selbst sind identisch mit den bestehenden V4-Varianten. Neu ist lediglich ein Modul, das die Inferenz beschleunigt.
Doch der scheinbar unscheinbare Release ist strategisch bedeutsamer als jede neue Modellgeneration. Denn DSpark adressiert das eigentliche Problem der KI-Industrie: die Kosten der Inferenz, also der Phase, in der ein trainiertes Modell tatsächlich genutzt wird. Während das Training eines Frontier-Modells einmalig hohe Kosten verursacht, fallen die Inferenzkosten kontinuierlich an — bei jedem API-Aufruf, jeder Chat-Anfrage, jeder Code-Generierung.
Die Technik dahinter ist elegant. Spekulative Dekodierung beschleunigt große Sprachmodelle, indem sie die Token-für-Token-Generierung in eine parallele Batch-Überprüfung umwandelt. Ein leichtgewichtiges „Entwurfsmodell" generiert vorab mehrere Kandidaten-Token, die das Zielmodell dann in einem Durchgang verifiziert. DeepSeek hat dieses Prinzip mit DSpark auf eine neue Stufe gehoben. Das Framework kombiniert eine semi-autoregressive Architektur — die die Vorteile der parallelen Generierung mit einem leichten seriellen Modul verbindet — mit einem konfidenzgesteuerten Überprüfungsmechanismus, der die Verifikationslänge dynamisch an die aktuelle Systemauslastung anpasst.
Die Ergebnisse sind beeindruckend. Im Vergleich zur vorherigen Produktionsbasislinie (MTP-1) steigert DSpark die Generierungsgeschwindigkeit einzelner Nutzer um 60 bis 85 Prozent, während der Gesamtdurchsatz unverändert bleibt. Die Akzeptanzlänge — also die Anzahl der Token, die pro Zyklus akzeptiert werden — liegt 26 bis 31 Prozent höher als beim bisherigen Spitzenreiter Eagle3 und 16 bis 18 Prozent höher als bei DFlash. Und das alles ohne Qualitätsverlust: DSpark erhält die Ausgabeverteilung des Zielmodells exakt.
Die strategische Bedeutung dieser Optimierung lässt sich kaum überschätzen. Denn während US-Unternehmen wie OpenAI und Anthropic Milliarden in immer größere Modelle und immer teurere Trainingsläufe investieren — OpenAI und Anthropic werden 2026 zusammen schätzungsweise 65 Milliarden Dollar allein für Computing, Training und Betrieb ausgeben —, zielt DeepSeek auf die Kostenstruktur der Nutzungsphase. Wenn ein Unternehmen wie Lindy, eine KI-Agenten-Plattform, seinen gesamten Betrieb auf DeepSeek V4 umstellt und dabei Millionen von Dollar spart, bei gleichzeitiger Leistungssteigerung in Kernanwendungen, dann ist das kein Randphänomen mehr.
Der Preis als Waffe
Die Kostenunterschiede zwischen chinesischen und US-amerikanischen KI-Modellen sind inzwischen so extrem, dass sie die Marktstruktur neu formen. DeepSeek V4 Flash kostet 0,14 Dollar pro Million Input-Token und 0,28 Dollar pro Million Output-Token. OpenAI GPT-5.5 kostet 5 Dollar pro Million Input-Token und 30 Dollar pro Million Output-Token. Anthropics Claude Opus 4.7 kostet 5 Dollar pro Million Input-Token und 25 Dollar pro Million Output-Token. Das macht DeepSeek auf dem Input rund 36-mal günstiger und auf dem Output über 100-mal günstiger als GPT-5.5.
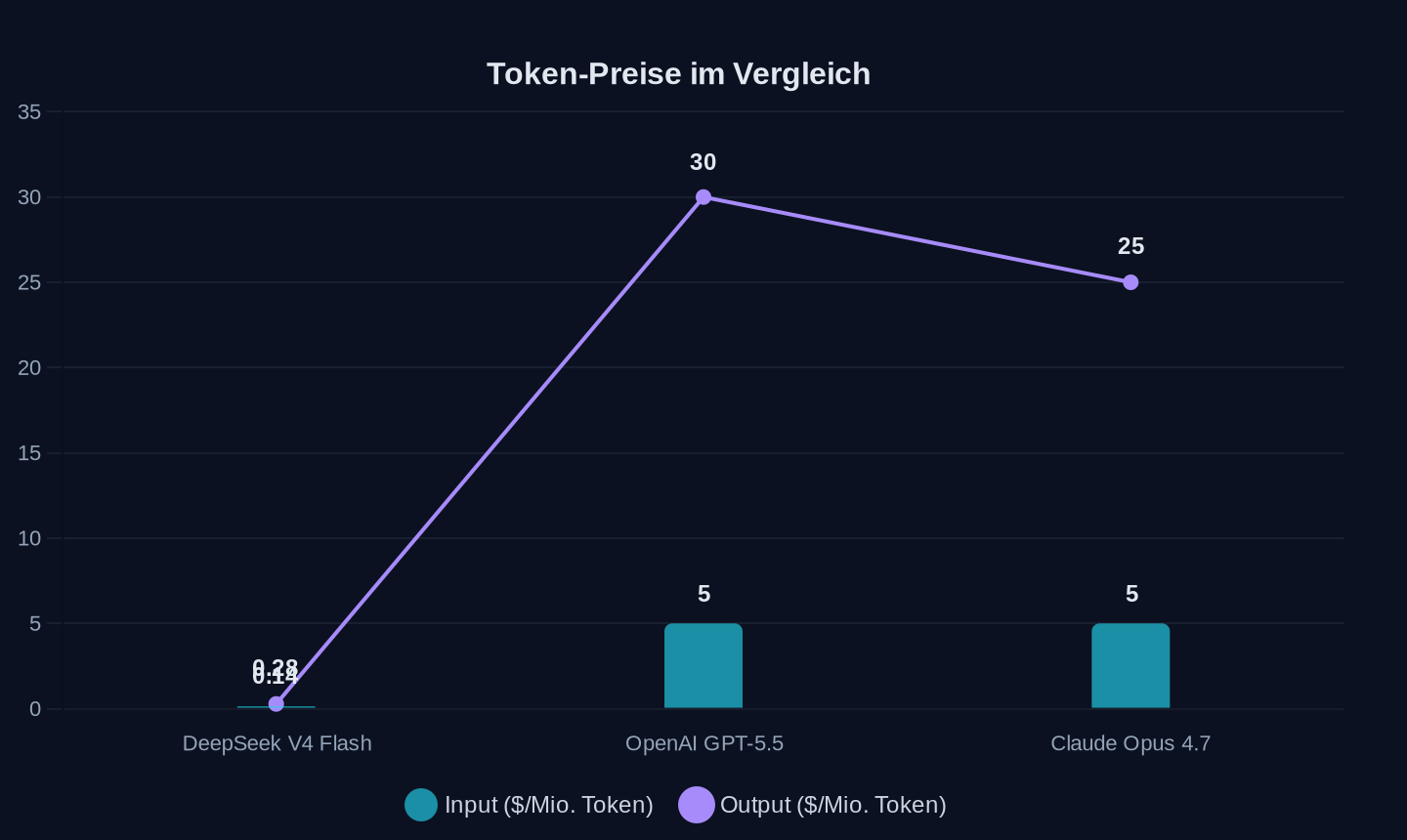 Preise pro Million Token (Input/Output) in US-Dollar
Preise pro Million Token (Input/Output) in US-Dollar
Diese Zahlen sind kein Geheimnis. Sie sind öffentlich einsehbar. Und sie erklären, warum die Token-Volumen auf OpenRouter sich so dramatisch verschoben haben. DeepSeek allein kommandiert 16,3 Prozent des gesamten Token-Volumens auf der Plattform — mehr als jeder andere Anbieter, vor Google (13,2 Prozent), Anthropic (15,5 Prozent) und OpenAI (8,7 Prozent). Die chinesischen Anbieter in den Top 10 — DeepSeek, Xiaomi, Tencent, MiniMax, Qwen — kommen zusammen auf rund 44 Prozent des Token-Volumens.
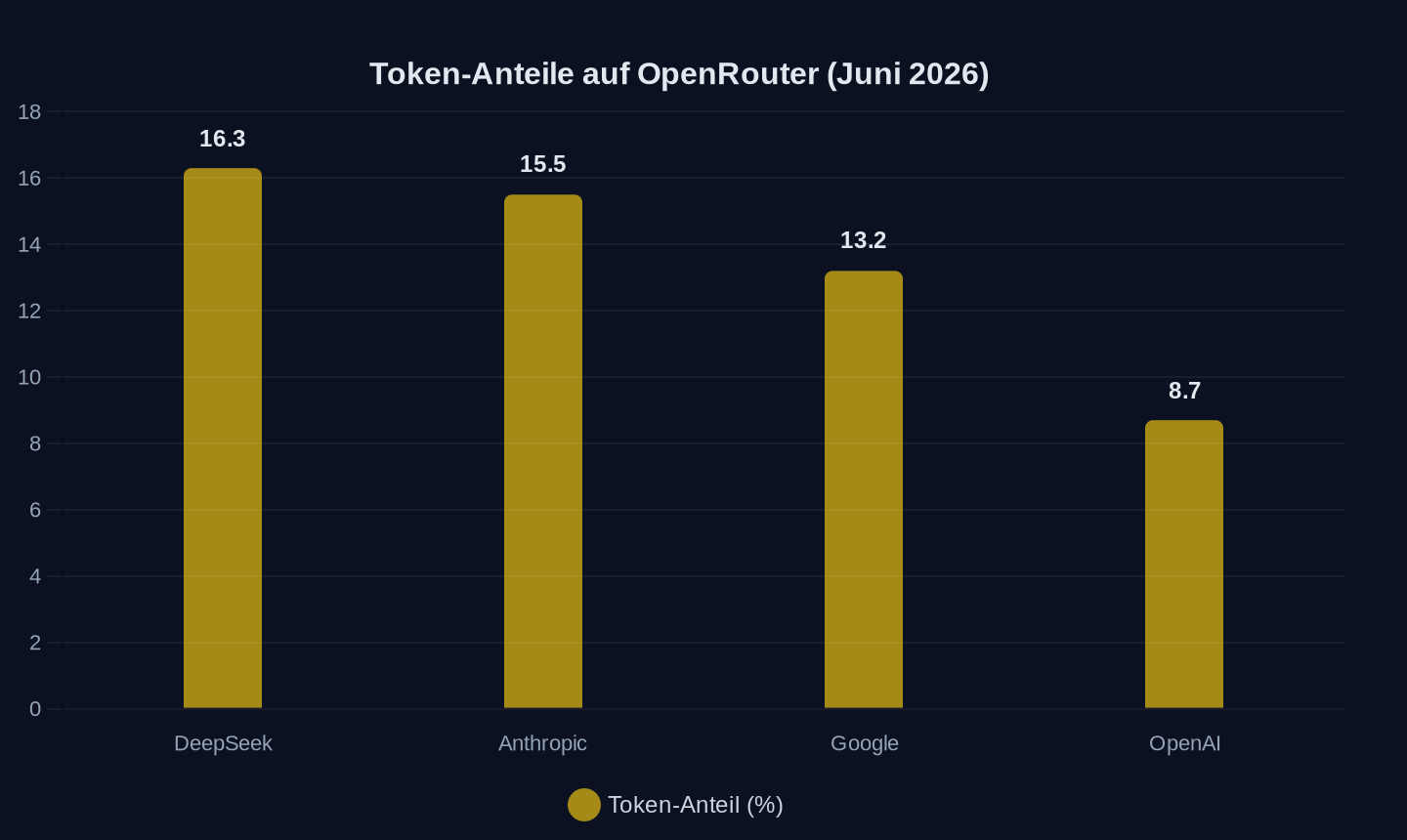 Anteil am gesamten Token-Volumen auf OpenRouter (in Prozent)
Anteil am gesamten Token-Volumen auf OpenRouter (in Prozent)
Die Migration findet nicht nur bei kleinen Entwicklern statt. Flo Crivello, CEO der KI-Agenten-Plattform Lindy, wechselte sein gesamtes Unternehmen auf DeepSeek V4. Der Grund: Millionen von Dollar an Einsparungen bei gleichzeitiger Leistungssteigerung in Kernanwendungen. Lindy ist kein Hobbyprojekt. Es ist eine finanzierte Produktionsplattform. Der Wechsel war das Ergebnis monatelanger systematischer Benchmarking.
Die Kostenstruktur chinesischer Modelle ist jedoch nicht nur eine Frage der reinen Effizienz. Sie ist auch strukturell bedingt. Chinesische Modelle sind in nicht-englischen Märkten systematisch günstiger: Die Token-Kosten für Chinesisch sind bis zu zehnmal niedriger als für Englisch. Das schafft einen Wettbewerbsvorteil im Globalen Süden, wo Englisch nicht die primäre Sprache ist. Selbst führende US-Unternehmen wie Airbnb setzen Qwen in ihrem LLM-Stack ein, um die mehrsprachige Unterstützung zu verbessern.
Das Ende der US-Dominanz
Die OpenRouter-Daten der vergangenen zwölf Monate sind das klarste Signal, das die Industrie produziert hat. Der Anteil der US-Modelle am Token-Volumen fiel von 70 auf 30 Prozent. Chinesische Modelle besetzen sechs der zehn Spitzenplätze. Die beiden Modelle an der Spitze — DeepSeek V4 Flash und Tencent Hy3 Preview — verzeichneten ein monatliches Wachstum von nahezu 1.000 Prozent.
Anthropic-CEO Dario Amodei hat gegen diese Entwicklung argumentiert. Chinesische Modelle seien auf Benchmarks optimiert und von US-Laboren destilliert, sagte er. Die rohe Leistungsfähigkeit — nicht der Preis — bestimme die langfristige Adoption. Diese Position hat mehr Glaubwürdigkeit, wenn sie von einem Labor kommt, dessen Modelle in den aktuellen Daten eine Ausnahme darstellen: Claude Opus 4.7 hält den dritten Platz auf dem OpenRouter-Ranking, das höchstrangige Closed-Source-Modell. Die Nutzung der Claude-Familie hat sich über mehrere Zyklen chinesischer Modellveröffentlichungen als stabil erwiesen.
Doch für die US-Modelle insgesamt stützen die Zahlen Amodeis Optimismus nicht. OpenAI liegt auf OpenRouter inzwischen auf Platz vier nach Unternehmen, weit hinter DeepSeek. Der Markt, der sich um GPT-4 als die unangefochtene erste Wahl für jede ernsthafte KI-Anwendung gebildet hatte, existiert in dieser Form nicht mehr.
Die Verschiebung zeigt sich auch in den Unternehmensausgaben. Der Ramp AI Index für Juni 2026 führt DeepSeek in der Kategorie der grundlegenden LLMs an — nicht nur diskutiert, sondern tatsächlich bezahlt von realen Unternehmen, die ihre Workloads auf die API routen. Das ist bedeutsam, weil Unternehmensadoption tendenziell klebrig ist. Wenn ein Team Infrastruktur um ein Modell herum aufbaut und die Wechselkosten steigen, kehren sie nicht unbedingt zu einer teureren Alternative zurück, selbst wenn diese sich verbessert.
Der Schwarzmarkt als Innovationstreiber
Während die offiziellen Kanäle sich verschieben, existiert parallel ein florierender Untergrundmarkt. Anthropic geht nach eigenen Angaben große Mühen, um Menschen in China die Nutzung seiner Modelle zu verwehren. In der Praxis sind diese Sicherheitsvorkehrungen jedoch oft gescheitert. Über das vergangene Jahr haben Startups, Forscher und Technikbegeisterte in ganz China zunehmend ausgefeilte Workarounds entwickelt, um auf Claude zuzugreifen. Viele von ihnen betrachten es als das leistungsfähigste KI-Assistenten der Welt, was die zusätzliche Mühe rechtfertigt.
Anfang Juni veröffentlichte Anthropic Fable 5, eine abgesicherte Version seines bis dahin leistungsfähigsten Modells Mythos. Die chinesischen sozialen Medien erleuchteten sofort mit Beiträgen von Menschen, die ihre ersten Eindrücke teilten. (Anthropic entzog den Zugang zum Modell weltweit wenige Tage später als Reaktion auf Exportkontrollen der Trump-Administration.)
Chinesische Nutzer können im Allgemeinen auf andere westliche KI-Tools wie ChatGPT zugreifen, indem sie virtuelle private Netzwerke, ausländische Telefonnummern und internationale Zahlungsmethoden nutzen. Aber Anthropic hat nach eigenen Angaben aggressivere Schritte unternommen, wie das Sperren von Konten, bei denen der Verdacht besteht, dass sie von in China ansässigen Personen kontrolliert werden. In den chinesischen sozialen Medien berichten Nutzer häufig, dass sie ohne Vorwarnung von Claude suspendiert wurden, trotz dieser Vorsichtsmaßnahmen.
Das Katz-und-Maus-Spiel hat eine florierende Untergrundwirtschaft für Claude-Zugang in China befeuert. Konten werden auf chinesischen E-Commerce-Plattformen wie Taobao und auf illegalen Marktplätzen auf Telegram verkauft. In jüngerer Zeit ist eine Hausindustrie von „Transferstationen" entstanden. Diese Dienste fungieren als Vermittler, kaufen Zugang zur Anthropic-API außerhalb Chinas und verteilen dann Claude-API-Tokens an Nutzer innerhalb des Landes. Das Setup ist darauf ausgelegt, Startups und anderen professionellen Nutzern stabileren und zuverlässigeren Zugang zu bieten.
Michael Aciman, ein Sprecher von Anthropic, sagte, das Unternehmen verwende eine Reihe sich entwickelnder Erkennungssysteme, einschließlich Identitätsverifikation, um seine Richtlinien gegen unbefugten Zugriff durchzusetzen. Er fügte hinzu, dass Anthropic auch daran gearbeitet habe, Proxy-Netzwerke zu erkennen und zu stören, die für den Zugriff auf den Chatbot in China genutzt werden.
Trotz aller Schwierigkeiten, die chinesische Nutzer überwinden müssen, um Claude zu nutzen, gibt es weiterhin viele loyale Fans von Anthropic im Land. Besonders beliebt ist es bei Programmierern. Obwohl chinesische Unternehmen wie DeepSeek und Z.ai einige der leistungsfähigsten Open-Source-Sprachmodelle auf dem Markt haben, zeigen Tests von Drittanbietern immer noch, dass sie hinter führenden Closed-Source-Modellen wie Claude zurückbleiben. Während einer kürzlichen Reportagereise nach China sprach WIRED mit Akademikern und Ingenieuren bei mehreren Technologieunternehmen, die sagten, sie bevorzugten Claude gegenüber chinesischen Modellen zur Code-Generierung.
Zilan Qian, Forschungsassistent am Oxford China Policy Lab, untersuchte den Schwarzmarkt für den Weiterverkauf westlicher KI-Tokens an chinesische Nutzer. Er stellte fest, dass chinesische Softwareentwickler nach eigenen Angaben überwältigend Tools wie Claude Code und OpenAIs Codex gegenüber Tools von inländischen Unternehmen bevorzugen. „Analysen zeigen, dass chinesische Modelle immer noch sechs bis neun Monate hinter den US-Modellen zurückliegen, und bei spezifischen Dingen wie Programmierung und Entwicklung kann man die Lücke deutlich erkennen", sagte Qian.
Matt Sheehan, Senior Fellow bei der Carnegie Endowment for International Peace, wo er KI-Politik und China erforscht, sieht eine asymmetrische Wahrnehmung: „Sowohl für chinesische KI-Politikmacher als auch für technische Leute haben sie viel weniger Probleme damit, amerikanische Ideen oder Produkte zu nutzen, unabhängig von der geopolitischen oder ideologischen Rivalität. Es sind die Amerikaner, die dazu neigen zu denken, eine Idee oder ein Produkt sei allein deshalb verdorben, weil es von ihrem Rivalen kommt."
Der Rückschlag der Exportkontrollen
Die US-Exportkontrollen, die Chinas Zugang zu fortschrittlichen KI-Chips beschränken sollen, haben einen paradoxen Effekt. Statt den chinesischen Fortschritt zu bremsen, beschleunigen sie Innovationen bei der Effizienz. DeepSeek trainierte sein R1-Modell für geschätzte 5,6 Millionen Dollar — ein Bruchteil der 100 Millionen Dollar oder mehr, die für GPT-4 veranschlagt werden — auf nur 2.048 H800-GPUs. Die Beschränkungen zwingen chinesische Unternehmen, mit weniger Ressourcen mehr zu erreichen.
Die Wirksamkeit der Exportkontrollen wird zunehmend in Frage gestellt. DeepSeek und andere chinesische Unternehmen liefern trotzdem Spitzenmodelle. Die Beschränkungen haben offenbar Innovationen bei der Effizienz ausgelöst, die nun weltweit Maßstäbe setzen. Die chinesische KI-Industrie hat gelernt, mit weniger auszukommen — und ist dadurch in mancher Hinsicht sogar effizienter geworden als ihre US-Konkurrenten.
Die geopolitischen Implikationen sind erheblich. Anthropic-CEO Dario Amodei warnt regelmäßig vor chinesischem Zugang zu Frontier-Modellen als Sicherheitsrisiko. Doch während er warnt, nutzen chinesische Entwickler Claude massiv, und US-Firmen wie Airbnb setzen chinesische Modelle (Qwen) ein. Die Grenzen zwischen den Ökosystemen sind durchlässiger, als die politischen Debatten suggerieren.
Die asiatischen Wettbewerber haben auf die Exportkontrollen mit eigenen Modellen reagiert. Die japanische Sakana AI startete Fugu, ein Modell, das nach eigenen Angaben auf dem Niveau führender Modelle wie Anthropics Fable 5 und Mythos Preview liegt. Sakana-CEO David Ha begründet die Strategie hinter Fugu als Reaktion auf US-Exportkontrollen: Zugang zu Top-Modellen könne über Nacht verschwinden. Kollektive Intelligenz sei die praktische Absicherung gegen diese Machtkonzentration. Die chinesische Firma 360 enthüllte Tulongfeng, ein KI-Tool zur automatischen Erkennung von Software-Sicherheitslücken, das nach eigenen Angaben mit Mythos mithalten kann.
Die Exportkontrollen haben also nicht verhindert, dass chinesische und asiatische Unternehmen Frontier-Modelle entwickeln. Sie haben lediglich dazu geführt, dass diese Unternehmen eigene Wege gehen — und dabei oft effizienter sind als ihre US-Konkurrenten.
Die neue Architektur der KI
Der Wettbewerb um große Modelle hat eine systemische Phase erreicht, in der Training und Inferenz gleichermaßen wichtig sind. Die Veröffentlichung von DeepSpec, der vollständigen Codebibliothek zum Trainieren und Bewerten von spekulativen Dekodierungs-Entwurfsmodellen, zeigt, wohin die Reise geht. DeepSeek öffnet nicht nur seine Modelle, sondern auch die Werkzeuge, mit denen andere ihre eigenen Modelle optimieren können. Das ist eine strategische Entscheidung: Je mehr Entwickler DeepSpec nutzen, desto stärker wird das Ökosystem um DeepSeek herum.
Die Architektur der KI verändert sich grundlegend. Hybride Architekturen werden zum Unternehmensstandard. Die Frage ist nicht mehr, welches Modell man wählt, sondern wie man ein System gestaltet, das verschiedene Modelle, Bereitstellungsmodi und Kostenstrukturen kombiniert. Zoom zum Beispiel verwendet für seinen KI-Assistenten eine hybride Architektur, die Kunden einen Federated Mode oder Isolated Mode bietet, um Leistung, Kosten und Datenschutz auszugleichen.
Die Fragmentierung des KI-Ökosystems schreitet voran. Es entstehen regionale Champions und hybride Architekturen. Die US-Dominanz, die noch vor zwei Jahren als unerschütterlich galt, bröckelt. Der Anteil der US-Modelle am globalen KI-Markt sinkt, während chinesische und asiatische Modelle aufholen.
Die Frage ist nicht mehr, ob China aufholt. Die Frage ist, wie schnell die Verschiebung stattfindet. Die OpenRouter-Daten deuten darauf hin, dass der Prozess bereits in vollem Gange ist. Der Anteil der US-Modelle ist in zwölf Monaten von 70 auf 30 Prozent gefallen. Wenn dieser Trend anhält, werden US-Modelle innerhalb eines weiteren Jahres auf dem wichtigsten neutralen Marktplatz für KI-Modelle zur Minderheit.
Die Kosten der Ignoranz
Die deutsche und europäische Industrie steht vor einer strategischen Entscheidung. Während die politische Debatte in Berlin und Brüssel sich auf Datenschutz und Regulierung konzentriert, verschieben sich die realen Machtverhältnisse in der KI-Industrie. Die Kostenstruktur chinesischer Modelle ist so attraktiv, dass Unternehmen wie Lindy systematisch wechseln. Der Preisunterschied ist kein Randphänomen mehr — er ist strukturell.
Für VW, BMW, Bosch und andere deutsche Industrieunternehmen bedeutet das: Die KI-Infrastruktur, die sie für ihre Produktion, ihre Logistik und ihre Produkte benötigen, wird zunehmend von chinesischen Anbietern dominiert. Die Abhängigkeit von US-Hardware (Nvidia) könnte sich auflösen, aber nur, um durch eine neue Abhängigkeit von chinesischer Software ersetzt zu werden.
Die europäische Industriepolitik hat auf diese Entwicklung keine Antwort. Während die EU chinesische E-Autos mit Zöllen belegt und über KI-Regulierung debattiert, bauen chinesische KI-Unternehmen ihre Marktposition aus. Die strukturellen Kostenvorteile chinesischer Modelle — niedrigere Token-Preise, bessere Unterstützung nicht-englischer Sprachen, offene Architekturen — sind kein vorübergehendes Phänomen. Sie sind das Ergebnis jahrelanger strategischer Investitionen und technologischer Innovation.
Die deutsche Industrie muss sich fragen, ob sie bereit ist, auf die günstigste und effizienteste KI-Infrastruktur zu verzichten, nur weil sie aus China kommt. Oder ob sie pragmatisch die besten Werkzeuge nutzt, unabhängig von ihrer Herkunft. Die Antwort auf diese Frage wird darüber entscheiden, ob die deutsche Industrie im KI-Zeitalter wettbewerbsfähig bleibt.
Die chinesischen KI-Unternehmen haben ihre Lektion gelernt: Effizienz schlägt rohe Kraft. Während US-Firmen in teuren Trainings-Wettrüsten stecken, haben chinesische Unternehmen die Inferenz-Effizienz zur strategischen Waffe gemacht. DeepSeek hat gezeigt, dass man mit schlauen Algorithmen mehr erreichen kann als mit immer größeren Modellen. Die Disruption ist nicht das Modell. Es ist die Systemoptimierung.
Und der Westen hat es nicht kommen sehen.
Die Illusion der Benchmark
Die technischen Fähigkeiten chinesischer KI-Modelle sind unbestreitbar. DeepSeek V4-Pro übertrifft Claude Opus 4.6 in mehreren Tests und belegt Spitzenplätze in HLE und Codeforces. Doch die Frage, die im Westen selten gestellt wird, ist eine andere: Sind diese Benchmarks wirklich ein verlässlicher Indikator für industrielle Nutzbarkeit?
Die Antwort ist komplizierter, als es die Marketingabteilungen der chinesischen KI-Unternehmen wahrhaben wollen. Patronus AI, ein Startup, das von ehemaligen Meta-KI-Forschern gegründet wurde und kürzlich 50 Millionen Dollar in einer Series B einsammelte, hat ein Geschäftsmodell darauf aufgebaut, genau diese Lücke zu schließen. Das Unternehmen baut simulierte digitale Umgebungen, in denen KI-Agenten unter realistischen Bedingungen getestet werden – nicht auf standardisierten Benchmarks, sondern in Nachbildungen realer Websites und interner Systeme.
Glenn Solomon, Managing Director bei Notable Capital, beschreibt die Nachfrage nach diesen simulierten Umgebungen als „nahezu unstillbar". Der Umsatz von Patronus ist im vergangenen Jahr um das Fünfzehnfache gestiegen. Praktisch jedes Frontier-KI-Labor und viele aufstrebende Startups sind inzwischen Kunden. Das deutet auf ein tiefsitzendes Misstrauen gegenüber den offiziellen Benchmark-Zahlen hin – auch bei den Unternehmen, die diese Modelle selbst entwickeln.
Das Problem ist ein grundsätzliches. KI-Labore nutzen Benchmarks oft, um die Leistungsfähigkeit ihrer Modelle zu demonstrieren, aber ein hoher Punktwert, selbst in einem agentenorientierten Benchmark, beweist nicht, dass eine KI komplexe, reale Aufgaben korrekt ausführen kann. KI-Agenten neigen dazu, Abkürzungen zu nehmen, was bedeutet, dass sie die Aufgabe nicht korrekt abschließen. „Patronus ist wirklich gut darin, die Hacks zu erkennen und sicherzustellen, dass die Modelle rechenschaftspflichtig bleiben", sagt Solomon.
Die Implikation für chinesische Modelle ist erheblich. Während DeepSeek und andere auf standardisierten Tests glänzen, fehlt eine unabhängige Überprüfung ihrer Leistungsfähigkeit in realistischen Szenarien durch Dritte. Die chinesischen Unternehmen selbst veröffentlichen Benchmark-Zahlen, aber die Methodik ist oft intransparent. Die Frage, ob chinesische Modelle in der industriellen Produktion, in der Logistik oder im Finanzwesen tatsächlich halten, was sie versprechen, bleibt offen.
Die Zuverlässigkeit von KI wird zum nächsten großen Thema. Patronus AI konzentriert sich derzeit auf überprüfbare Probleme – solche, die man sofort prüfen und verifizieren kann. Aber es gibt „eine Menge weiterer Bereiche, die sehr schwer zu verifizieren sind", sagt Mitgründer Anand Kannappan. Das Unternehmen will Umgebungen schaffen, in denen ein Agent zehn Stunden oder zehn Tage oder zehn Wochen lang laufen kann. Für chinesische Modelle, die oft für den schnellen Einsatz optimiert sind, könnte die Langzeit-Zuverlässigkeit zur Achillesferse werden.
Die Geldmaschine
Hinter den technischen Durchbrüchen verbirgt sich eine finanzielle Dynamik, die im Westen kaum verstanden wird. Die chinesische KI-Industrie wird mit Kapital überschwemmt. Im ersten Quartal 2026 sicherten sich KI-bezogene Startups in China mehr als 110 Milliarden Yuan – umgerechnet 16,2 Milliarden Dollar. Das entspricht einem Anstieg von 185 Prozent gegenüber dem Vorjahreszeitraum. Der KI-Boom hat den gesamten chinesischen Private-Equity- und Venture-Capital-Markt beflügelt: 2.568 Deals im Wert von 234,4 Milliarden Yuan im Märzquartal, ein Anstieg von 5 Prozent bei der Deal-Anzahl und über 15 Prozent beim Wert.
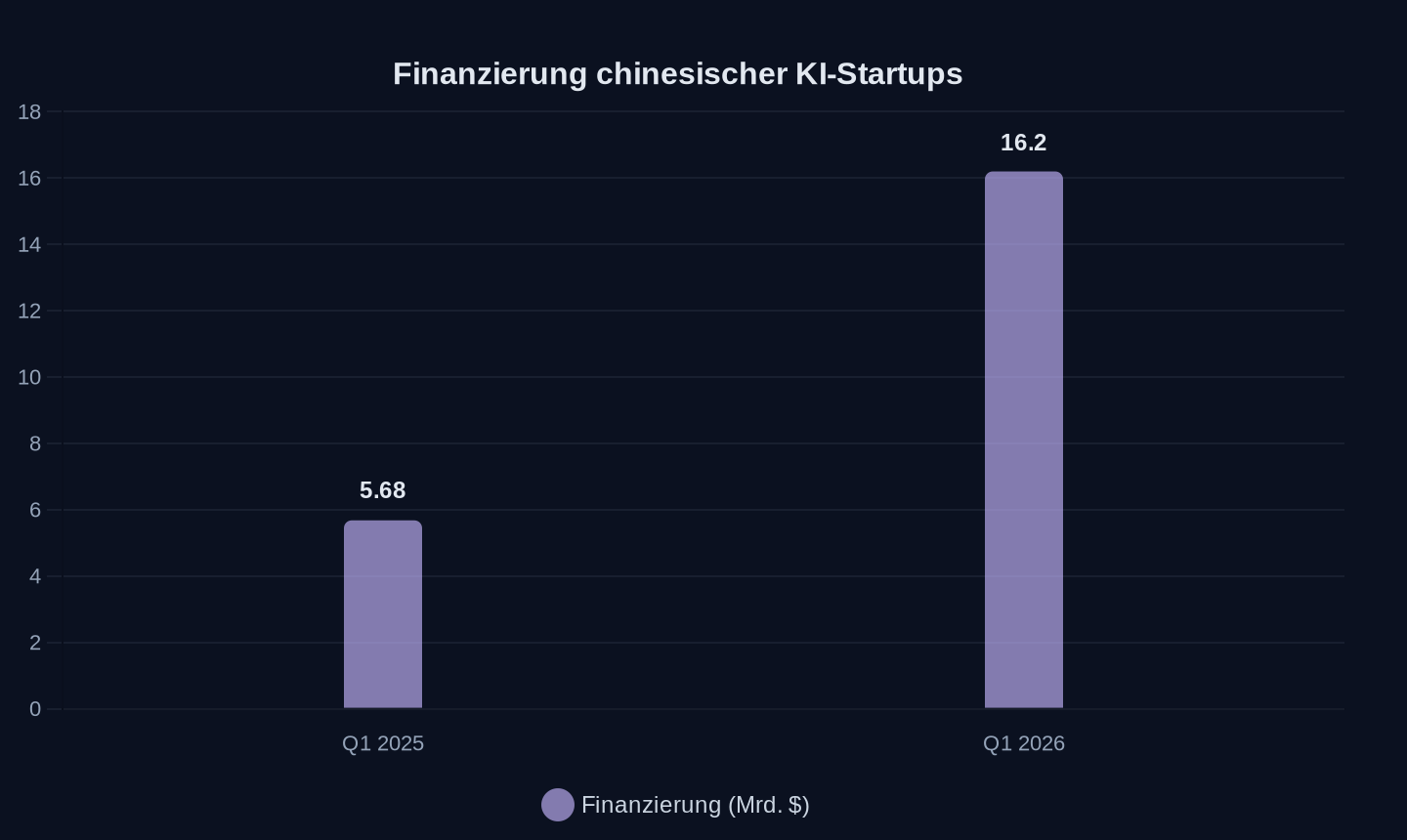 Finanzierung chinesischer KI-Startups im ersten Quartal (in Milliarden US-Dollar)
Finanzierung chinesischer KI-Startups im ersten Quartal (in Milliarden US-Dollar)
Diese Zahlen sind beeindruckend, aber sie werfen eine Frage auf, die in den Quellen nur am Rande behandelt wird: Wie nachhaltig ist dieses Ökosystem wirtschaftlich? Viele chinesische KI-Startups verbrennen Geld, und der Preiskampf ist brutal. Die durchschnittliche Profitrate in der chinesischen KI-Industrie ist niedrig, und viele Unternehmen sind auf staatliche Unterstützung oder die Finanzierung durch große Konzerne angewiesen.
Die Finanzinfrastruktur, die hinter diesen Unternehmen steht, ist komplex. Airwallex, ein Unternehmen, das als „Finanzverwalter" für KI-Startups wie Kimi, Zhipu und MiniMax fungiert, schloss kürzlich eine Serie-H-Finanzierungsrunde in Höhe von 320 Millionen Dollar ab und wurde zu einem Super-Einhorn mit einer Bewertung von 11 Milliarden Dollar. Die Einnahmen aus den USA stiegen im Jahresvergleich um 170 Prozent. Der Kapitalmarkt betrachtet Airwallex nicht mehr nur als grenzüberschreitende Zahlungsplattform, sondern positioniert es als globale Finanzinfrastruktur des KI-Zeitalters.
Die Herausforderungen, die Airwallex für seine KI-Kunden löst, sind symptomatisch für die Branche. KI-Unternehmen rechnen nicht mehr pro Sitzplatz ab, sondern pro Token. Die Token-Preise sind nicht einheitlich, sondern staffeln sich je nach Nutzerumfang und Dienst. B2B-Kunden haben Budgetkontrollanforderungen, was bedeutet, dass das System den Nutzer automatisch von einem Modell mit hohem Token-Verbrauch auf ein Modell mit niedrigerem Verbrauch umschalten muss, wenn die Ausgaben ein bestimmtes Niveau erreichen.
„Kunden achten oft zuerst darauf, wie viel Geld ausgegeben wurde, nicht darauf, wie viele Token verbraucht wurden", sagt Wu Kai, Chief Revenue Officer von Airwallex. Das bedeutet, dass das Abrechnungssystem den Rechenleistungsverbrauch jedes Nutzers in Echtzeit verfolgen und gleichzeitig mit dem KI-Unternehmen für den Modellwechsel zusammenarbeiten muss. Es ist ein Verbundproblem, das Zahlung, Abrechnung und Geschäftslogik umfasst.
Die finanzielle Komplexität wird durch die globale Natur des KI-Geschäfts noch verstärkt. KI-Unternehmen müssen Zahlungen in mehreren Währungen abwickeln, grenzüberschreitende Transaktionen durchführen und internationale Vorschriften einhalten. Viele Teams haben noch nicht einmal einen Finanzexperten mit globaler Erfahrung eingestellt. Airwallex unterstützt Zahlungen in über 200 Ländern und Regionen weltweit, wobei in über 120 Ländern und Regionen Zahlungen über lokale Abwicklungsnetzwerke möglich sind.
Die Frage der Nachhaltigkeit bleibt jedoch unbeantwortet. Die chinesische KI-Industrie wächst rasant, aber sie wächst auf einem Fundament, das noch nicht getestet wurde. Der Preiskampf könnte die Margen so weit drücken, dass viele Startups nicht überleben. Die Abhängigkeit von staatlicher Unterstützung und Konzernfinanzierung macht das Ökosystem anfällig für politische und wirtschaftliche Schocks.
Der Energie-Fluch
Die KI-Industrie hat ein Energieproblem, das im Westen wie im Osten gleichermaßen ignoriert wird. US-Rechenzentren verbrauchten 2025 schätzungsweise 224 Terawattstunden Strom – mehr als 5 Prozent des US-Gesamtverbrauchs. Das ist ein signifikanter Anstieg von geschätzten 1,9 Prozent im Jahr 2018, lange vor dem Mainstream-Aufschwung der generativen KI.
Die Kosten für diesen Energieverbrauch sind nicht nur finanziell, sondern auch ökologisch. Nach einer Schätzung aus dem Jahr 2025 könnten US-Rechenzentren bald das Äquivalent von 24 bis 44 Megatonnen CO2 pro Jahr ausstoßen – letzteres entspricht den jährlichen Emissionen Norwegens. Ein Großteil dieses Stroms wird von Gaskraftwerken erzeugt, weil Rechenzentren oft an Orten gebaut werden, die nicht über reichlich erneuerbare Energiequellen verfügen.
Die chinesische KI-Industrie steht vor denselben Herausforderungen, aber mit einem zusätzlichen Problem: China ist der größte Kohleverstromer der Welt. Während die USA zumindest teilweise auf Erdgas setzen, das weniger CO2 emittiert als Kohle, ist der chinesische Strommix noch kohlelastiger. Die Energiekosten für KI-Rechenzentren in China sind daher nicht nur ökologisch problematisch, sondern auch politisch heikel – China hat sich verpflichtet, bis 2060 klimaneutral zu werden.
Die Ironie ist, dass die chinesische KI-Industrie, die sich durch Effizienz auszeichnet, in einem der ineffizientesten Energiesysteme der Welt operiert. Die Rechenzentren, die die Modelle trainieren und betreiben, verbrauchen enorme Mengen an Strom, und dieser Strom kommt zu einem erheblichen Teil aus Kohlekraftwerken. Die Umweltbilanz der chinesischen KI-Revolution ist daher deutlich schlechter als die ihrer US-Konkurrenten.
Die Lösung dieses Problems könnte jedoch ebenfalls aus China kommen. Chinesische Wissenschaftler haben kürzlich einen Durchbruch bei supraleitenden Magneten für die Kernfusion erzielt – eine Technologie, die theoretisch unbegrenzte, saubere Energie liefern könnte. China hat den weltweit größten Fusionsreaktor-Supraleitungsmagneten fertiggestellt – eine 582 Tonnen schwere toroidale Feldspule – und einen vollständig im Inland produzierten Hochtemperatur-Supraleitungs-Solenoiden mit international führenden Leistungsdaten getestet.
Doch die Kernfusion ist noch Jahre, wenn nicht Jahrzehnte von der kommerziellen Nutzung entfernt. Bis dahin wird die KI-Industrie weiterhin enorme Mengen an Strom verbrauchen, und die Umweltkosten werden steigen. Die Frage ist, ob die Effizienzgewinne durch Technologien wie DSpark ausreichen, um den steigenden Energiebedarf zu kompensieren – oder ob die KI-Industrie an ihrem eigenen Energiehunger ersticken wird.
Die Stunde der Wahrheit
Die chinesische KI-Industrie hat in den vergangenen achtzehn Monaten eine Entwicklung durchgemacht, die im Westen als „Sputnik-Moment" bezeichnet wurde, aber in Wirklichkeit weit mehr ist. Es ist nicht nur ein technologischer Durchbruch. Es ist eine strukturelle Verschiebung der globalen KI-Architektur.
Die US-Exportkontrollen, die den chinesischen Fortschritt bremsen sollten, haben das Gegenteil bewirkt. Sie haben chinesische Unternehmen gezwungen, effizienter zu werden, und sie haben ein Ökosystem geschaffen, das in der Lage ist, mit weniger Ressourcen mehr zu erreichen. Die Kostenstruktur chinesischer Modelle ist so attraktiv, dass Unternehmen weltweit systematisch wechseln – nicht aus ideologischen Gründen, sondern aus rein wirtschaftlichen.
Die Frage, die jetzt im Raum steht, ist nicht, ob China aufholt. Sondern ob der Westen bereit ist, die Konsequenzen zu akzeptieren. Die chinesische KI-Industrie ist nicht mehr der Verfolger. Sie ist derjenige, der die Kosten senkt, die Effizienz steigert und die Standards setzt. Und der Westen hat noch nicht einmal begonnen, die Antwort zu formulieren.
Die deutsche Industrie, die auf KI angewiesen ist, um wettbewerbsfähig zu bleiben, steht vor einer Wahl. Sie kann weiterhin auf teure US-Modelle setzen und hoffen, dass die Preise irgendwann fallen. Oder sie kann pragmatisch die günstigste und effizienteste Lösung wählen – und damit de facto akzeptieren, dass die KI-Infrastruktur der Zukunft aus China kommt.
Die Antwort auf diese Frage wird nicht in Berlin oder Brüssel entschieden. Sie wird in den Rechenzentren entschieden, in denen Ingenieure und Entwickler täglich die Wahl treffen, welches Modell sie für ihre Arbeit nutzen. Und wenn die OpenRouter-Daten ein Indikator sind, dann haben sie ihre Wahl bereits getroffen.
Quellen
- China is having another AI moment
- Is Chinese AI roaring back?
- Repositioning retail for the AI era
- The emergence of the web data infrastructure layer for AI
- Rocket Report: China may soon attempt booster landing; Rocket Lab does rapid response
- How People in China Keep Outsmarting Anthropic’s Geolocation Restrictions
- 梁文锋署名论文,DeepSeek首轮融资后大动作:生成速度大涨85%
- 刚刚,DeepSeek V4更新DSpark,推理速度提升80%
- 谁在帮头部 AI 公司 “管钱” ?一个百亿美元超级独角兽的诞生
- China and North Korea absorb lessons from Ukraine's evolving battlefield
- Honda starts AI data center battery production in US after EV pivot
- China Achieves Breakthrough in Nuclear Fusion Superconducting Magnets
- 从 Cerebras IPO 聊起:AI 算力变化、Scaling law 的萌芽和百度美研往事
- AI Collapses on a Classic Psychology Test. What It Reveals Could Stall Human-Level AI.
Weitere Artikel

Chinas humanoide Roboter montieren sich selbst — und der Westen debattiert über Verbote
27. Juni 2026

Hangzhou, 3 Uhr: Warum Chinas KI jetzt schneller denkt als die USA zahlen können
27. Juni 2026

„Intelligence and knowledge have to come together“ – Chinas Wette auf die KI-Infrastruktur
27. Juni 2026

Chips ohne ASML: Wie Huawei das Mooresche Gesetz umschreibt – und was das für den Westen bedeutet
27. Juni 2026

Chinas Chips skalieren nicht kleiner – sie skalieren schneller
27. Juni 2026

Chinas Chip-Industrie verdrängt Nvidia durch gestapelte Transistoren vom heimischen Markt
27. Juni 2026

Wer profitiert wirklich von Europas Zoll-Schachzug gegen China?
27. Juni 2026

Was passiert, wenn Chinas Batterie-Zulieferer die Autohersteller erpressen
27. Juni 2026

Europas Städte kaufen Überwachung als Verkehrssteuerung
26. Juni 2026

Chinas Batterie-Revolution kommt ohne Festkörper – warum der Westen falsch liegt
26. Juni 2026

80 Prozent Erfolg in 52 Grad Hitze – Chinas KI-Infrastruktur wächst im Schatten
25. Juni 2026

Geschlossen, subventioniert, skaliert – Chinas Chip-Ökosystem entsteht
25. Juni 2026